
- About Us
- Information
-

The Author ensures that the research has been conducted responsibly and ethically with adherence to all relevant regulations. read more..
- For Authors
- For Reviewer
- Manuscript Guidelines
- Membership
- Publication Ethics
-
- Journals
- Reprints
- e-Books
- Videos
- Policies
- Contact Us
 COVID-19
COVID-19
- Submissions



Full Text
Associative Journal of Health Sciences
Lessons Learned from Pooled Testing of Covid-19
William J Berger1*, Adam C Sales2, Konrad R Dabrowski3 and Jake A Robinson3
1Political Economy & Moral Science, University of Arizona, USA
2Department of Mathematical Sciences, Worcester Polytechnic Institute, USA
3Department of Biology, Temple University, USA
*Corresponding author: William J Berger, Political Economy & Moral Science, University of Arizona, USA
Submission: July 25, 2022;Published: August 02, 2022

ISSN:2690-9707 Volume2 Issue1
Abstract
The Coronavirus pandemic set off a flurry of research and reports on a wide range of concerns for the health sciences. One of these concerns has been an interest in effective monitoring, tracing, and testing of the disease on a mass scale. The acute and emergent nature of the crisis precipitated a need not only for greater monitoring capacity, but one which could scale at a mass level and at a reduced cost. The reduction of costs was crucial not only for greater efficiencies as capacity was taxed, but also for prevalence testing in low income and developing countries. This paper offers a review of the pooled testing literature around the Covid-19 pandemic, identifying developments in the field as well as paths forward for new variants or future public health emergencies.
Keywords:COVID; Cost-benefit analysis; Prevalence testing; Batch testing
Introduction
Early papers offer straightforward models of group testing samples in order to quickly determine the presence of biomarkers in large groups [1-4]. The pressing need during Covid-19 to conduct high-volume testing surpassed antecedents like the HIV epidemic [5,6]. The Covid-19 pandemic brought renewed attention to this older literature by stretching and overwhelming public health infrastructure and demanding an increased testing capacity at a massive scale [7]. This acute need, combined with its global reach, rekindled an interest in both comprehensive and low-cost testing techniques in order to monitor population level contagion as well as identify at-risk individuals who would serve as vectors for spread..
Pooled testing offers two distinct, but interrelated advantages to one-off sample testing. At first, pooled (or batched) testing allows for the evaluation of a large number of samples at once, thereby making possible streamlined and low-cost population-level prevalence testing. Here, the goal is not to identify infected individuals, but to assess population disease levels. Along with random sampling, pooled testing allows for high levels of population accuracy with a diminished capacity. Second, however, is the prospect of accomplishing individual level monitoring. Here, depending on assumptions of prevalence within a population, tests can be batched with repeating, but not overlapping, individual samples allowing for pooled testing to accomplish both population and individual level assessments. This paper offers a review of developments in the literature on both the theory of pooled testing as well as its practice in laboratory and clinical sites during the Covid-19 pandemic.
Theory
The basic case underlying pooled testing is a binomial model which assumes a random probability of an event being realized in one of two ways, positive or negative cases. The aim is to test some number of people N, in groups of size n. Assume at first that there are no false negatives or false positives and that the cost to test a batch of samples, cb, is no less than the cost of testing an individual sample, ci. Indeed, there are a number of aspects of the PCR diagnostic panel that must be implemented on each sample, making perfect streamlining impossible. However, the signal amplification of the PCR test means that much of the process remains the same for batched as for individual tests. The cost of implementing the batched technique will be cb in the case that the batch tests negative, and cb+nci in the case where the batch tests positive. This is because if even one member of the group tests positive, each person’s sample will need to be run individually1. Assuming each batch is a random subset of the population, the probability that the group will test negative is (1-p)n, where p is the prevalence in the local population.
The expected cost of one batched test is:
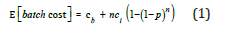
Given N total people, N/n batched tests will yield a total expected cost of:
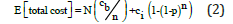
Under individual testing, the total cost is Nci, so the expected cost of pooling relative to individual testing is:
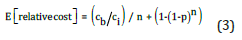
Figure 1: Cost schedule for pooled testing for various prevalence levels.

Figure 1 plots the expected relative costs for a range of values of p. In the first panel cb=ci, and in the second and third cb is two and three times ci, respectively2. These latter two more accurately reflect the realities of implementing RT-qPCR from respiratory specimens. PCR isolation of viral RNA is a labor-intensive process, even prior to cDNA synthesis and amplification of target sequences [8]. There are thus inevitably process-based hurdles which limit the value of cb/ci on the high end. The bolded horizontal line running parallel to the x-axis reflects the break-even point, where batch and individual testing are equally efficient in expectation [9]. Above the line (cost equal to 1.0) individual testing is preferable, and below pooled testing.
1In circumstances where we only care about prevalence testing and not individual testing, this constraint will diminish,
as there is no compelling reason to subsequently run the test on the individual samples. Moreover, if the type I error rate
is greater than 1/n, such individual level testing wouldn’t be warranted. The type I error rate greater than 1/n doesn’t
undermine the usefulness of prevalence testing, however, since on average we would still reckon that the aggregate accuracy
would remain 1-ɑ.
2The cost of a batch test cb presumably depends on the size of the batch, n; we set it to a constant for the sake of simplicity.
This background is given to illustrate the statistical and financial elements of the problem, but they are not formally much advanced from early papers [1-3]. These early papers sought to estimate optimal group size given an underlying prevalence of an organism or pathogen in some larger set of samples. There were advances on statistical approaches to pooled testing shortly before the pandemic [10], but many others quickly followed during the peak of the outbreak [11-17]. Mathematical results, using a simulated set of 2304 samples, and prevalences of anywhere from 0.2% to 20% support a potential 400-fold reduction in testing infrastructure [18]. Moreover, while pooled testing was initially conceived as a means of prevalence testing across a population a “mini-pool” design can be overlayed on traditional methods allowing for greater efficiencies as well as individual-level monitoring [19].
The Dorfman method was extended using computational approaches by evaluating the optimal parameters for pooling given sensitivity considerations [20]. Here cutoffs for pooling size are identified using a computational approach while establishing optimal threshold values for Ct the number of RCP cycles required to mark a positive sample. However, especially with higher rates of prevalence, a context sensitive approach most successfully reduces costs, grouping samples together where there is an ex-ante reason to suspect higher prevalence, or projecting social network analyses on sampling choices [9,11].
Beyond computational approaches, fascinating analytical results offered exponential efficiencies on the traditional methods. While the Dorfman method offers theoretical efficiency on the order of 2p, these methods amplify such efficiency to an order of (e)(p) ln(p), where p is a non-large prevalence [20]. Such techniques along with employing subsample pooling on a hypercube algorithm, have the merit of addressing both desiderata above-namely prevalence testing and identifying individual positive cases [13,20]. Indeed, under optimal conditions a single positive individual could be identified in a pool of one million samples with only 39 tests [13]. Such advances on the theoretical foundations of the Dorfman algorithm provide massive efficiencies moving forward for Covid-19 as well as other large scale public health events to come.
Practice
In practice pooled testing became widely used across many domains including university systems, large international cities, developing countries, and even receiving a strong endorsement by the FDA [21-23]. The CDC did, however, later raised concerns about the adequacy of pooling to identify individual cases, while EU guidance further reflected the limitations of pooling for antigen (rather than PCR) testing [24,25]. But the efficiencies cannot be undersold. The city of Qingdao, China was able to test its entire population of more than seven million in less than three days [20]. And in Germany pooled testing was found to reduce the number of tests required by anywhere from 24% to 93% [26].
The practical consideration, beyond the theoretical ones, were paramount during the peak of the pandemic. But the sheer scale of the public health emergency opened up empirical and observational research on an order that pooled testing could be conducted. Work in Italy reported using pools as large as 30 samples, with Ct values up to 34 cycles, while work in Spain found that smaller pools of five enabled Ct values up to 39.4 [7,15]. Importantly and impressively, Israeli results assessed 133,816 Covid-19 PCR tests in order to evaluate real-world implications of pooled testing [27]. This study is distinguished in both its observational nature-rather than analytic or simulated results-and the scale at which it operated. The results were striking. Operating with prevalence levels between 0.5% and 6%, results exceeded theoretical expectations both for group size and Ct cycles. And while they were not directly able to estimate levels of false negatives, only one pool on retest was found misidentified, a NPV of 99.91%.
Collectively, these results indicate the practical, real-world efficacy of pooled testing. While much of the literature had heretofore focused on theoretical results driven by analytical solutions of statistical models, the wide adoption of pooled testing and subsequent confirmatory scientific literature offers unparalleled endorsement of the practice.
Conclusion
Pooled sample testing is not a recent innovation, but, with the notable exception of the HIV epidemic, had not received wide consideration in the medical science literature prior to the Covid-19 outbreak. The global and emergent nature of the public health event created novel demands for broad and efficient responses which would be widely implemented. Pooled testing proved an effective procedure for population and individual level surveillance, with diverse successes-from well-resourced OECD countries to under-resourced domains in the global south. Innovations were offered both on the analytic side demonstrating closed form as well as algorithmic solutions for more efficient practices as well as in applied, real-world circumstances. The review here provides an overview of these achievements and advances and should serve as an indication of the strong successes of the program as well as insights for future opportunities to combat global health emergencies.
Acknowledgement
The authors would like to thank the anonymous reviewers for their helpful comments along the way, as well as Ellen Hertzmark for her thoughtful input.
Competing Interests
The authors declare that they have no competing interests in the drafting of this paper.
References
- McCrady MH (1915) The numerical interpretation of fermentation-tube results. The Journal of Infectious Diseases 17(1): 183-212.
- Dorfman R (1943) The detection of defective members of large populations. The Annals of Mathematical Statistics 14(4): 436-440.
- Sobel M, Groll PA (1966) Binomial group-testing with an unknown proportion of defectives. Techno-metrics 8(4): 631-656.
- Chen CL, Swallow WH (1990) Using group testing to estimate a proportion, and to test the binomial model. Biometrics 46(4): 1035-1046.
- Tamashiro H, Fauquex A, Heymann D, Emmanuel J, Sato P, et al. (1993) Reducing the cost of HIV antibody testing. The Lancet 342(8863): 87-90.
- Tu XM, Litvak E, Pagano M (1994) Screening tests: Can we get more by doing less? Statistics in Medicine 13(19-20): 1905-1919.
- Lohse S, Pfuhl T, Berkó Göttel B, Rissland J, Geißler T, et al. (2020) Pooling of samples for testing for SARS-CoV-2 in asymptomatic people. The Lancet Infectious Diseases 20(11): 1231-1232.
- Centers for Disease Control (2020) CDC 2019-novel coronavirus (2019-nCoV) real- time RT-PCR diagnostic panel.
- Lin YJ, Yu CH, Liu TH, Chang CS, Chen WT (2021) Positively correlated samples save pooled testing costs. IEEE Transactions on Network Science and Engineering 8(3): 2170-2182.
- Nguyen NT, Bish EK, Aprahamian H (2018) Sequential prevalence estimation with pooling and continuous test outcomes. Statistics in Medicine 37(15): 2391-2426.
- Deckert A, Bärnighausen T, Kyei NN (2020) Simulation of pooled-sample analysis strategies for COVID-19 mass testing. Bulletin of the World Health Organization 98(9): 590-598.
- Mutesa L, Ndishimye P, Butera Y, Souopgui J, Uwineza A, et al. (2020) A strategy for finding people infected with SARS-CoV-2: optimizing pooled testing at low prevalence.
- Cohen A, Shlezinger N, Solomon A, Eldar YC, Médard M (2021) Multi-level group testing with application to one-shot pooled COVID-19 tests. In: ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) pp: 1030-1034.
- Lagopati N, Tsioli P, Mourkioti I, Polyzou A, Papaspyropoulos A, et al (2021) Sample pooling strategies for SARS-CoV-2 detection. Journal of Virological Methods 289: 114044.
- Alcoba Florez J, Gil Campesino H, De Artola DGM, Díez Gil O, Fernández AV, et al. (2021) Increasing SARS-CoV-2 RT-qPCR testing capacity by sample pooling. International Journal of Infectious Diseases 103: 19-22.
- Hogan CA, Sahoo MK, Pinsky BA (2020) Sample pooling as a strategy to detect community transmission of SARS-CoV-2. JAMA 323(19): 1967-1969.
- Torres I, Albert E, Navarro D (2020) Pooling of nasopharyngeal swab specimens for SARS‐CoV‐2 detection by RT‐PCR. Journal of Medical Virology. 92(11):2306-2307.
- Cleary B, Hay JA, Blumenstiel B, Harden M, Cipicchio M, et al. (2021) Using viral load and epidemic dynamics to optimize pooled testing in resource-constrained settings. Science Translational Medicine 13(589): eabf1568.
- Mahase E (2020) Covid-19: Universities roll out pooled testing of students in bid to keep campuses open. BMJ 370: m3789.
- Brault V, Mallein B, Rupprecht JF (2021) Group testing as a strategy for COVID-19 epidemiological monitoring and community surveillance. PLoS Computational Biology 17(3): e1008726.
- Mutesa L, Ndishimye P, Butera Y, Souopgui J, Uwineza A, et al (2021) A pooled testing strategy for identifying SARS-CoV-2 at low prevalence. Nature 589(7841): 276-280.
- Mercer TR, Salit M (2021) Testing at scale during the COVID-19 pandemic. Nature Reviews Genetics 22(7): 415-426.
- Food and Drug Administration (2020) Coronavirus (COVID-19) Update: FDA issues first emergency authorization for sample pooling in diagnostic testing.
- Centers for Disease Control (2021) Pooling testing: Summary of Updates.
- European Commission Directorate-General for Health and Food Safety (2022) EU Common list of COVID-19 rapid antigen tests.
- Sunjaya AF, Sunjaya AP (2020) Pooled testing for expanding COVID-19 mass surveillance. Disaster Medicine and Public Health Preparedness 14(3): e42-e43.
- Barak N, Ben Ami R, Sido T, Perri A, Shtoyer A, et al (2021) Lessons from applied large-scale pooling of 133,816 SARS-CoV-2 RT-PCR tests. Science Translational Medicine 13(589): eabf2823.
© 2022 William J Berger. This is an open access article distributed under the terms of the Creative Commons Attribution License , which permits unrestricted use, distribution, and build upon your work non-commercially.
Editor In Chief







.jpg)

























Signup for Newsletter

Quick Links
 Editorial Board Registrations
Editorial Board Registrations Submit your Article
Submit your Article Refer a Friend
Refer a Friend Advertise With Us
Advertise With UsOur Recent Edition

.jpg)



Top Editors




.jpg)

















.bmp)
.jpg)
.png)
.jpg)













.jpg)






.png)

.png)




.png)




Financial Support

Sponsors

Latest e-Books

Latest Video

 a Creative Commons Attribution 4.0 International License. Based on a work at www.crimsonpublishers.com.
Best viewed in
a Creative Commons Attribution 4.0 International License. Based on a work at www.crimsonpublishers.com.
Best viewed in